On Thu 11-10-12 11:52:54, Viktor Nagy wrote:The FPC is not so clever. If you write Test(i*10). It gives the same hint:On 2012.10.10. 22:27, Jan Kara wrote:You get a hint about automatic conversion from 'integer' to 'int64'? IOn Wed 10-10-12 22:44:41, Viktor Nagy wrote:Well, you get a hint at least (FPC 2.6).On 10/10/2012 06:57 PM, Jan Kara wrote:Actually I somewhat doubt that even FreePascal is able to give you aHello,Sorry for the bug and maybe the poor implementation. I am much
On Tue 09-10-12 11:41:16, Viktor Nagy wrote:Since Kernel version 3.0 pdflush blocks writes even the dirty bytesI've run your program and I can confirm your results. As a side note,
are well below /proc/sys/vm/dirty_bytes or /proc/sys/vm/dirty_ratio.
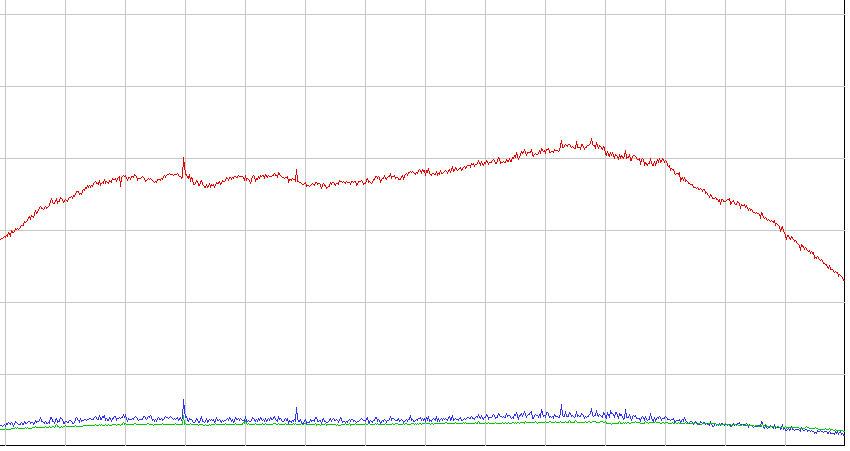
The kernel 2.6.39 works nice.
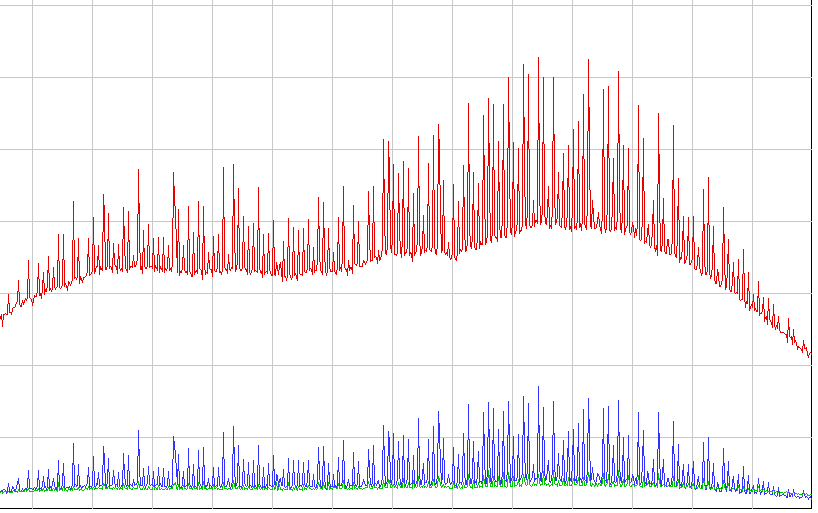
How this hurt us in the real life: We have a very high performance
game server where the MySQL have to do many writes along the reads.
All writes and reads are very simple and have to be very quick. If
we run the system with Linux 3.2 we get unacceptable performance.
Now we are stuck with 2.6.32 kernel here because this problem.
I attach the test program wrote by me which shows the problem. The
program just writes blocks continously to random position to a given
big file. The write rate limited to 100 MByte/s. In a well-working
kernel it have to run with constant 100 MBit/s speed for indefinite
long. The test have to be run on a simple HDD.
Test steps:
1. You have to use an XFS, EXT2 or ReiserFS partition for the test,
Ext4 forces flushes periodically. I recommend to use XFS.
2. create a big file on the test partiton. For 8 GByte RAM you can
create a 2 GByte file. For 2 GB RAM I recommend to create 500MByte
file. File creation can be done with this command: dd if=/dev/zero
of=bigfile2048M.bin bs=1M count=2048
3. compile pdflushtest.c: (gcc -o pdflushtest pdflushtest.c)
4. run pdflushtest: ./pdflushtest --file=/where/is/the/bigfile2048M.bin
In the beginning there can be some slowness even on well-working
kernels. If you create the bigfile in the same run then it runs
usually smootly from the beginning.
I don't know a setting of /proc/sys/vm variables which runs this
test smootly on a 3.2.29 (3.0+) kernel. I think this is a kernel
bug, because if I have much more "/proc/sys/vm/dirty_bytes" than the
testfile size the test program should never be blocked.
your test program as a bug as it uses 'int' for offset arithmetics so when
the file is larger than 2 GB, you can hit some problems but for our case
that's not really important.
better in Pascal than in C.
(You can not make such mistake in Pascal (FreePascal). Is there a
way (compiler switch) in C/C++ to get there a warning?)
warning that arithmetic can overflow...
program inttest;
var
i,j : integer;
procedure Test(x : int64);
begin
Writeln('x=',x);
end;
begin
i := 1000000;
j := 1000000;
Test(1000000*1000000);
Test(int64(i)*j);
Test(i*j); // result is wrong, but you get a hint here
don't have a fpc compiler at hand to check that but I'd be surprised
because that tends to be rather common. I imagine you get the warning if
the compiler can figure out the numbers in advance. But in your test
program the situation was more like:
ReadLn(i);
j = 4096;
Test(i*j);
And there the compiler nows nothing about the resulting value...
Ok, it is very hard to get an overview about this whole thing.Which documentation do you mean exatly? The process won't be throttledI've just tested it. After I've set the dirty_bytes over the fileRunning without that commit should work just fine unless you useThe regression you observe is caused by commit 3d08bcc8 "mm: Wait forThank you for your response!
writeback when grabbing pages to begin a write". At the first sight I was
somewhat surprised when I saw that code path in the traces but later when I
did some math it's clear. What the commit does is that when a page is just
being written out to disk, we don't allow it's contents to be changed and
wait for IO to finish before letting next write to proceed. Now if you have
1 GB file, that's 256000 pages. By the observation from my test machine,
writeback code keeps around 10000 pages in flight to disk at any moment
(this number fluctuates a lot but average is around that number). Your
program dirties about 25600 pages per second. So the probability one of
dirtied pages is a page under writeback is equal to 1 for all practical
purposes (precisely it is 1-(1-10000/256000)^25600). Actually, on average
you are going to hit about 1000 pages under writeback per second which
clearly has a noticeable impact (even single page can have). Pity I didn't
do the math when we were considering those patches.
There were plans to avoid waiting if underlying storage doesn't need it but
I'm not sure how far that plans got (added a couple of relevant CCs).
Anyway you are about second or third real workload that sees regression due
to "stable pages" so we have to fix that sooner rather than later... Thanks
for your detailed report!
Honza
I'm very happy that I've found the right people.
We develop a game server which gets very high load in some
countries. We are trying to serve as much players as possible with
one server.
Currently the CPU usage is below the 50% at the peak times. And with
the old kernel it runs smoothly. The pdflush runs non-stop on the
database disk with ~3 MByte/s write (minimal read).
This is at 43000 active sockets, 18000 rq/s, ~40000 packets/s.
I think we are still below the theoratical limits of this server...
but only if the disk writes are never done in sync.
I will try the 3.2.31 kernel without the problematic commit
(3d08bcc8 "mm: Wait for writeback when grabbing pages to begin a
write").
Is it a good idea? Will it be worse than 2.6.32?
something exotic like DIF/DIX or similar. Whether things will be worse than
in 2.6.32 I cannot say. For me, your test program behaves fine without that
commit but whether your real workload won't hit some other problem is
always a question. But if you hit another regression I'm interested in
hearing about it :).
size the writes are never blocked.
So it's working nice without the mentioned commit.
The problem is that if you read the kernel's documentation about the
dirty page handling it does not work that way (with the commit) It
works unpredictable.
because of dirtying too much memory but we can still block it for other
reasons - e.g. because we decide to evict it's code from memory and have to
reload it again when the process gets scheduled. Or we can block during
memory allocation (which may be needed to allocate a page you write to) if
we find it necessary. There are no promises really...
Honza
Attachment:
perfgraph_linux_3.2.PNG
Description: PNG image
Attachment:
perfgraph_linux_2.6.32.PNG
Description: PNG image
{kind=link}
{kind=link}