On Sat, 5 Jan 2002, Ingo Molnar wrote:
>
> On Fri, 4 Jan 2002, Davide Libenzi wrote:
>
> > [...] but do you remember 4 years ago when i posted the priority queue
> > patch what you did say ? You said, just in case you do not remember,
> > that the load average over a single CPU even for high loaded servers
> > is typically lower than 5.
>
> yep, this might have been the case 4 years ago :) But i'd not be ashamed
> to change my opinion even if i had said it just a few months ago.
>
> Today we have things like the slashdot effect that will break down
> otherwise healthy and well-sized systems. People have started working
> around things by designing servers that run only a limited number of
> processes, but the fact is, why should we restrict application maker's
> choice of design, especially if they are often interested in robustness
> more than in the last bit of performance. There are a fair number of
> real-world application servers that start to suffer under Linux if put
> under realistic load.
No Ingo the fact that you coded the patch this time does not really change
the workloads, once you've a per-cpu run queue and lock. The thing that
makes big servers to suffer in the common queue plus the cache coherency
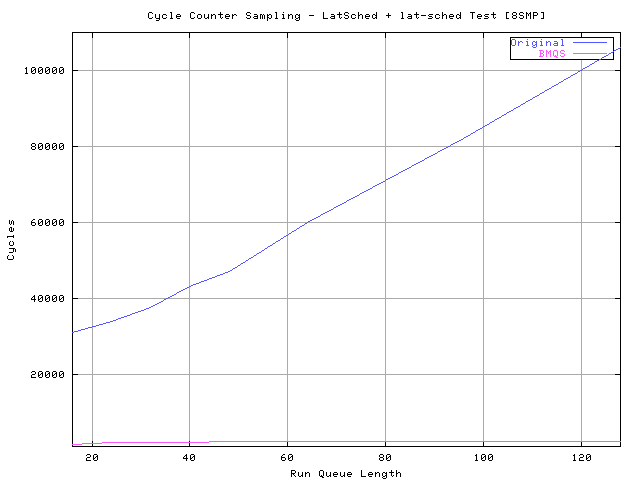
traffic due the common lock. Look here for an 8 way system :
http://www.xmailserver.org/linux-patches/lats8-latsch.png
In even _high_realistic_ workloads on these servers the scheduler impact
is never more than 5-15% and by simply splitting the queue/lock you get a
30 up to 60 time fold ( see picture ), that makes the scheduler impact to
go down to 0.2-0.3%. Why do you need to overoptimize for a 0.2% ?
> > Yes, 70% of the cost of a context switch is switch-mm, and this
> > measured with a cycle counter. [...]
>
> two-process context switch times under the O(1) scheduler did not get
> slower.
No makes the scheduler more complex and with a bigger memory footprint.
It's a classical example of overoptimization that you agreed time ago to
be unnecessary. By having coded the patch this time seems to have changed
your mind :
/*
* linux/kernel/sched.c
*
* Kernel scheduler and related syscalls
*
* Copyright (C) 1991, 1992, 2002 Linus Torvalds, Ingo Molnar
*
> > Take a look at this if you do not believe :
>
> In fact it's the cr3 switch (movl %0, %%cr3) that accounts for about 30%
> of the context switch cost. On x86. On other architectures it's often
> much, much cheaper.
TLB flushes are expensive everywhere, and you know exactly this and if you
used a cycle counter to analyze the scheduler instead of silly benchmarks
you would probably know more about what inside a context switch does matter.
Just to give you an example, the cost of a context switch :
CS = CMC + MMC + N * GLC
with :
CMC = common path cost
MMC = switch MM cost
N = number of tasks on the run queue
GLC = cost of a goodness() loop
Do you know what is, in my machine, the value of N that makes :
CMC + MMC = N * GLC
Well, it's 10-12, that means a runqueue with 10-12 running processes.
What does this mean, it means that is almost useless to optmize for O(1)
because (CMC + MMC) is about one order of magnitude about GLC.
And a run queue of 10 is HUGE for a single CPU, as long a run queue of 80
is again pretty HUGE for an 8 way SMP system.
And you've the history on Linux of the last 10 years that thought you that
such run queue are not realistic.
> > More, you removed the MM affinity test that, i agree that is not
> > always successful, but even if it's able to correctly predict 50% of
> > the reschedules, [...]
>
> you must be living on a different planet if you say that the p->mm test in
> goodness() matters in 50% of the reschedules. In my traces it was more
> like 1% of the cases or less, so i removed it as insignificant factor
> causing significant complexity. Please quote the specific workload/test i
> should try, where you think the mm test matters.
Oh sure you won't see this in benchmarks that but try to run a cycle
sampler with a yield()-test load and move your mouse. Look at the
context switch time when yield() tasks are switching and when the keventd
task get kicked. I'm not saying that the test will be always successful
but getting right even a percent of these switches is sure better than
trying to optimize a cost that is limited by way higher components.
> > Lets come at the code. Have you ever tried to measure the context
> > switch times for standard tasks when there's an RT tasks running ?
>
> the current RT scheduling scheme was a conscious choice. *If* a RT task is
> running (which just doesnt happen in 99.999% of the time) then scalability
> becomes much less important, and scheduling latency is the only and
> commanding factor.
> > You basically broadcast IPIs with all other CPUs falling down to get
> > the whole lock set. [...]
>
> oh yes. *If* a RT task becomes runnable then i *want* all other CPUs drop
> all the work they have as soon as possible and go try to run that
> over-important RT task. It doesnt matter whether it's SMP-affine, and it
> doesnt matter whether it's scalable. RT is about latency of action,
> nothing else. RT is about a robot arm having to stop in 100 msecs or the
> product gets physically damaged.
>
> this method of 'global RT tasks' has the following practical advantage: it
> reduces the statistical scheduling latency of RT tasks better than any
> other solution, because the scheduler *cannot* know in advance which CPU
> will be able to get the RT task first. Think about it, what if the CPU,
> that appears to be the least busy for the scheduler, happens to be
> spinning within some critical section? The best method is to let every CPU
> go into the scheduler as fast as possible, and let the fastest one win.
Ingo your RT code sucks and if you for a single second try to forget that
you coded the patch, you will be able to agree. The full lock acquisition
sucks, the broadcast IPI sucks ( just to not exaggerate ) and the fact
that while an RT task is running and the schedules that happens in the
system will try to pickup inside the RT queue ( trying to acquire the
whole lock set, each time ). Come on Ingo this looks very like the old
wakeup code before the wakeone has been implemented. There is absolutely
no reason that, in an 4/8 way smp system running an rt task on a cpu, the
other 3/7 should suffer for this. Try to open your eyes Ingo, you would
never accepted this code if it was coming from someone else.
> George Anzinger @ Montavista has suggested the following extension to this
> concept: besides having such global RT tasks, for some RT usages it makes
> sense to have per-CPU 'affine' RT tasks. I think that makes alot of sense
> as well, because if you care more about scalability than latencies, then
> you can still flag your process to be 'CPU affine RT task', which wont be
> included in the global queue, and thus you wont see the global locking
> overhead and 'CPUs racing to run RT tasks'. I have reserved some priority
> bitspace for such purposes.
I don't like to infringe patents but this is used inside the Balanced
Multi Queue Scheduler from the very beginning. A flag SCHED_RTLOCAL in
setscheduler() makes the difference.
> > static inline void update_sleep_avg_deactivate(task_t *p)
> > {
> > unsigned int idx;
> > unsigned long j = jiffies, last_sample = p->run_timestamp / HZ,
> > curr_sample = j / HZ, delta = curr_sample - last_sample;
> >
> > if (delta) {
> [...]
>
> > If you scale down to seconds with /HZ, delta will be 99.99% of cases
> > zero. How much do you think a task will run 1-3 seconds ?!?
>
> i have to say that you apparently do not understand the code. Please check
> it out again, it does not do what you think it does. The code measures the
> portion of time the task spends in the runqueue. Eg. a fully CPU-bound
> task spends 100% of its time on the runqueue. A task that is sleeping
> spends 0% of its time on the runqueue. A task that does some real work and
> goes on and off the runqueue will have a 'runqueue percentage value'
> somewhere between the two. The load estimator in the O(1) scheduler
> measures this value based on a 4-entry, 4 seconds 'runqueue history'. The
> scheduler uses this percentage value to decide whether a task is
> 'interactive' or a 'CPU hog'. But you do not have to take my word for it,
> check out the code and prove me wrong.
I'm sorry but you set p->run_timestamp to jiffies when the task is run
and you make curr_sample = j / HZ when it stops running.
If you divide by HZ you'll obtain seconds. A task typically runs 10ms to
60ms that means that, for example :
p->run_timestamp = N ( jiffies )
curr_sample = N+5 max ( jiffies )
with HZ == 100 ( different HZ does not change the picture ).
Now, if you divide by HZ, what do you obtain ?
unsigned long j = jiffies, last_sample = p->run_timestamp / HZ,
curr_sample = j / HZ, delta = curr_sample - last_sample;
delta will be ~97% always zero, and the remaining 3% one ( because of HZ
scale crossing ).
Now this is not my code but do you understand your code ?
Do you understand why it's broken ?
> > You basically shortened the schedule() path by adding more code on the
> > wakeup() path. This :
>
> would you mind proving this claim with hard numbers? I *have* put up hard
> numbers, but i dont see measurements in your post. I was very careful
> about not making wakeup() more expensive at the expense of schedule(). The
> load estimator was written and tuned carefully, and eg. on UP, switching
> just 2 tasks (lat_ctx -s 0 2), the O(1) scheduler is as fast as the
> 2.5.2-pre6/pre7 scheduler. It also brings additional benefits of improved
> interactiveness detection, which i'd be willing to pay the price for even
> if it made scheduling slightly more expensive. (which it doesnt.)
Oh, you've very likely seens my posts and they're filled of numbers :
http://www.xmailserver.org/linux-patches/mss.html
http://www.xmailserver.org/linux-patches/mss-2.html
And the study, being based on cycle counter measures is a little bit more
accurate than vmstat. And if you'd have used a cycle counter you'd have
probably seen where the cost of a context switch is and you'd have
probably worked trying to optimize something else instead of a goodness()
loop.
> > with a runqueue balance done at every timer tick.
>
> please prove that this has any measurable performance impact. Right now
> the load-balancer is a bit over-eager trying to balance work - in the -A2
> patch i've relaxed this a bit.
>
> if you check out the code then you'll see that the load-balancer has been
> designed to be scalable and SMP-friendly as well: ie. it does not lock
> other runqueues while it checks the statistics, so it does not create
> interlocking traffic. It only goes and locks other runqueues *if* it finds
> an imbalance. Ie., under this design, it's perfectly OK to run the load
> balancer 100 times a second, because there wont be much overhead unless
> there is heavy runqueue activity.
>
> (in my current codebase i've changed the load-balancer to be called with a
> maximum frequency of 100 - eg. if HZ is set to 1000 then we still call the
> load balancer only 100 times a second.)
Wow, only 100 times, it's pretty good. You're travelling between the CPU
data only 100 times per second probably trashing the running process cache
image, but overall it's pretty good code.
And please do not say me to measure something like this. This is that kind
of overload that you add to a system that will make you wake up one
morning with a bloated system without even being able to understand from
where it comes. You would never have been accepted a patch like this one
Ingo, don't try to sell it as good because you coded it.
> > Another thing that i'd like to let you note is that with the current
> > 2.5.2-preX scheduler the recalculation loop is no more a problem
> > because it's done only for running tasks and the lock switch between
> > task_list and runqueue has been removed. [...]
>
> all the comparisons i did and descriptions i made were based on the
> current 2.5.2-pre6/pre7 scheduler. The benchmarks i did were against
> 2.5.2-pre6 that has the latest code. But to make the comparison more fair,
> i'd like to ask you to compare your multiqueue scheduler patch against the
> O(1) scheduler, and post your results here.
>
> and yes, the goodness() loop does matter very much. I have fixed this, and
> unless you can point out practical disadvantages i dont understand your
> point.
What ? making the scheduler switch 60000000 times per seconds with 1245
tasks on the run queue ?! Please Ingo.
I did not seek this. I seeked this 4 years ago when you ( that did
not code the patch ) were on the other side saying that is useless to
optimize for O(1) because realistic run queue are < 5 / CPU. Do you
remember Ingo ?
Adding a multi level priority is no more than 10 minutes of code inside
BMQS but i thought it was useless and i did not code it. Even a dual queue
+ FIFO pickups :
http://www.xmailserver.org/linux-patches/mss-2.html#dualqueue
can get O(1) w/out code complexity but i did not code it. Two days ago
George Anziger proposed me to implement ( inside BMQS ) __exactly__ the
same thing that you implemented/copied ( and that he did implement before
you in his scheduler ) but i said to George my opinion about that, and George
can confirm this.
> fact is, scheduler design does matter when things are turning for the
> worse, when your website gets a sudden spike of hits and you still want to
> use the system's resources to handle (and thus decrease) the load and not
> waste it on things like goodness loops which will only make the situation
> worse. There is no system that cannot be overloaded, but there is a big
> difference between handling overloads gracefully and trying to cope with
> load spikes or falling flat on our face spending 90% of our time in the
> scheduler. This is why i think it's a good idea to have an O(1)
> scheduler.
Ingo please, this is too much even for a guy that changed his opinion. 90%
of the time spent inside the scheduler. You know what makes me angry ?
It's not that you can sell this stuff to guys that knows how things works
in a kernel, i'm getting angry because i think about guys actually reading
your words and that really think that using an O(1) scheduler can change
their life/system-problems. And they're going to spend their time trying
this stuff.
Again, the history of our UP scheduler thought us that noone has been able
to makes it suffer with realistic/high not-stupid-benchamrks loads.
Look, at the contrary of you ( that seem to want to sell your code ), i
simply want a better Linux scheduler w/out overoptimizations useful only
to grab the attention inside advertising inserts.
I give you credit to have cleaned sched.c but the guidelines for me are :
1) multi queue/lock
2) current dyn_prio/time_slice implementation ( the one in pre8 )
3) current lookup, that becomes simpler inside the CPU local run queue :
list_for_each(tmp, head) {
p = list_entry(tmp, struct task_struct, run_list);
if ((weight = goodness(p, prev->active_mm)) > c)
c = weight, next = p;
}
4) current recalc loop logic
5) _definitely_ better RT code
If we agree here we can continue working on the same code base otherwise
i'll go ahead with my work ( well it's more fun than work since my salary
in completely independent from this ).
- Davide
-
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@vger.kernel.org
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
This archive was generated by hypermail 2b29 : Mon Jan 07 2002 - 21:00:29 EST
{kind=link}